This article was published in Scientific American’s former blog network and reflects the views of the author, not necessarily those of Scientific American
Editor’s Note: The following is a guest post from Martin Krzywinski and Barbara Jeannie Hunnicutt, contributing artists who designed the Graphic Science illustration in the December 2015 issue of Scientific American magazine.
It turns out that the dust in your house carries telltale clues about who lives there—the relative numbers of men and women, and also the presence or absence of dogs and cats. That’s one of the conclusions of a paper titled “The ecology of microscopic life in household dust,” published in Proceedings of the Royal Society B. Our goal in the December 2015 Graphic Science page was to capture that finding visually.
What is in household dust, exactly? Pollen, hair, fibers, soil, skin cells and even meteorite particles. But plenty of bacteria, too: and a great variety of them, shed by the occupants of the home—including pets, who contribute their own unique bacterial bouquet. This may not be that surprising to you, if you’ve been licked by a dog or a cat—two very different experiences. The pet’s less savory parts, at least to humans (hint: the opposite end), contribute their own kinds of bacteria, too. Now, thanks to very fast and very cheap genome sequencing, it’s possible to study a sample of dust and collect a census of its inhabitants.
On supporting science journalism
If you're enjoying this article, consider supporting our award-winning journalism by subscribing. By purchasing a subscription you are helping to ensure the future of impactful stories about the discoveries and ideas shaping our world today.
The proportion of male and female human occupants was also found to have an impact on the bacterial flora, though to a lesser extent than the pets. This difference is affected by difference in skin biology and—humorously pointed out in the paper—body size and hygiene practices. We’ll leave it to you to guess which is the larger and/or the cleaner sex!
Direction and Design
An early idea for the design of the page was a personalized and interactive “choose your own dust adventure” decision tree that would direct the reader to discover the types of bacteria they would be likely to find in their dust at home through some kind of graphic (Figure 1).

Figure 1. The initial idea for the December 2015 Graphic Science page: a personalized and interactive decision chart that leads the reader to a panel that would somehow represent the composition of bacteria in the dust in their home.
What to Show?
We had to delve into the data to determine what, exactly, to display in the square panels in Figure 1. We wanted to identify patterns that were meaningful and could be easily represented in a relatively small space. At this early stage of a design sketch, it’s important to have (and discard) as many ideas as possible.
The data included relative abundances (the proportion of the bacterial population made up of each bacterial genus) for about 90 genera of bacteria—from Acinetobacter (phylum Spirochaetes) to Treponema (phylum Proteobacteria) sampled from about 1,400 households. For each household, we knew the number of male and female occupants and whether there were dogs or cats present. The number or gender of the pets was not collected, nor whether there were infants in the house.
We were initially guided by a figure from the study (Figure 2), which shows box plots for some of the bacteria that were found in significantly higher abundance in the presence of dogs or cats.

Figure 2. Differences in the proportion of indoor bacteria. Vertical axis is square-root transformed. Box plot outliers are not shown. (Adapted from "The ecology of microscopic life in household dust," By Albert Barberán et al., In Proceedings of the Royal Society B, Published 26 August 2015.)
Box plots can be an excellent way to compactly represent information about the sample—they show the median, inter-quartile range (IQR, the values between the 25% and 75% percentile) and, depending on the type of box plots, the distance to outliers. For example, in Tukey box plots the whisker length extends to outliers as far as 1.5 IQR beyond the 1st or 3rd quartiles. (You can make your own box plots with this handy online tool). In Figure 3 we show the box plots, with outliers, for a larger set of bacteria.

Figure 3. Box plots for all genera with abundance differences at P < 0.1 for households with dogs (vs no dogs) and cats (vs no cats). For each genus, white boxplots show samples from households with no pet and those colored by P value from households with a pet (dog or cat). Genera in top row are sorted by total abundance (decreasing) and in bottom row by P value (increasing).
Being able to generate this figure and reproduce the results of the paper was an important first step to verify our analysis methods. In Figure 4, we show the abundance distribution in the form of a histogram (bar chart) for a subset of the bacteria.

Figure 4. The impact of pet presence on the distribution of the abundance of nine genera of bacteria in household dust. Average and median of distributions are shown as solid and dashed vertical lines. Largest three absolute increases in average abundance for each pet condition is shown by a red arrow.
Figures 3 & 4 reveal important details about the data. First, abundance of genera varied greatly and was zero in many households, which we surmised from the fact that all the box plot whiskers ended at zero. Second, the distributions of abundances across households were right-skewed (they had a long tail at higher abundances). We expected averages and medians to vary greatly, which they did: the least abundant bacteria, Cryobacterium, had an average relative abundance of 0.8x10–6 and Corynebacterium, the most abundant bacteria, had an average of 5x10–2, about 6,000× larger. Even when the abundance differences were small, the large sample sizes (e.g. 796 and 569 households with and without dogs) provided sufficient statistical power to assign statistical significance to these differences.
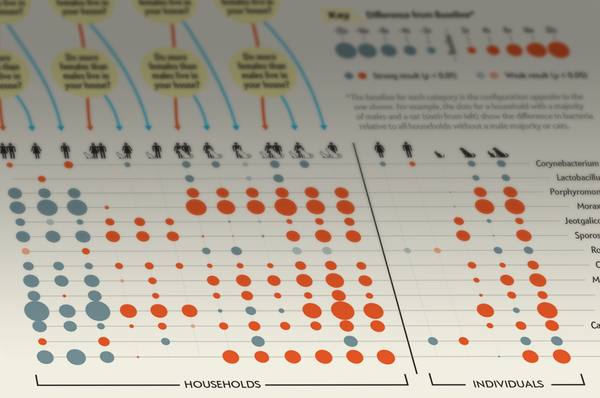
The original decision tree design idea meant that we had to create a contingency table that showed all possible combinations of our variables: males, females, cats and dogs. For example, we would need to distinguish households in which the majority of occupants were female and had dogs from households that had a male majority with cats, so we started to explore alternative display methods that would allow us to convey all of that information.
Initial designs
While box plots and histograms were useful for assessing the overall dataset, it was pretty clear from Figures 3 & 4 that they would not be ideal for the magazine. It’s difficult to see differences across bacteria at a glance, and the charts couldn’t be reduced to fit on one page and still be legible.
Our early design attempts are shown in Figure 5. We wanted to:
Encode the data in a way that could be represented in a series of small charts that could be cross-compared;
Make it easy for the reader to identify the variables and the bacterial changes they cause;
Encourage reader engagement by creating a visually interesting page; and
Provide a subtle nod to the subject matter at hand—bacterial communities—without falling prey to literal symbols such as petri dishes or DNA helixes (although we tried)!

Figure 5. Various approaches to encoding and design at the sketch phase. Although using bacterial shapes (size or color) to encode abundance seemed like a promising idea, they did not provide enough visual weight. Boilerplate text is used to get a sense of the page layout.

Figure 6. Early design elements, including absolute abundance histogram with detailed changes for each condition, data vignettes for largest abundance changes.
We had data for a lot more bacteria than we had room to display, so we considered showing an overview of the broader dataset, with details for only a subset (Figure 6, top right). This seemed promising, but didn’t fit well with the idea of the contingency table we wanted to create.
We did decide that it would be fun to use the actual shapes of the bacteria (Figure 7) to give each genus a distinct visual personality as an icon next to its label—we love Helicobacter!

Figure 7. Bacteria shapes give each genus a personality. Helicobacter needs a haircut.
Data Encoding
Encoding the differences in abundance as circles seemed to match our needs; circles allowed for a compact representation that made it easy to identify changes across conditions, as well as providing a subtle connection to the subject—think bacterial colonies.
The absolute changes in abundance varied greatly across bacteria, making it nearly impossible to compare them directly. Instead, we decided to show the relative change in abundance as a ratio of the average final abundance divided by the average baseline abundance. Given that the distributions are skewed (Figure 4), the median would be traditionally used instead of the average, but in some cases the median was zero, which would have prevented us from calculating a ratio. We used the log2 of the average ratios to indicate the difference—and used the concept of doubling in the legend key. This seemed more intuitive than a linear increase or some other logarithm base (e.g. log10), since the concept of a population doubling (or halving—think half-life of a decaying substance) is common.
Using circles (and thus area) to encode quantity is tricky. Most people tend to underestimate quantities when assessing areas because they use length as a proxy to guide their judgment, not considering that area is the square of the length. There are some clever techniques that scale the size of the circle to match how we perceive areas. (See "The Relative Effectiveness of Some Common Graduated Point Symbols in the Presentation of Quantitative Data," [PDF], By James Flanney, 1971; and "Proportional Symbol Mapping in R," by Susumu Tanimura et al., 2006). Instead of scaling the radius as x0.5, where x is the quantity being encoded, we used x0.57 (suggested by Flanney) which subtly increases the area. Finally, we chose the maximum size of the circle to ensure that the circles do not overlap in the final graphic.
Since each value describes the increase or decrease relative to a baseline level of bacterial abundance, choosing the baseline for each contingency was an exercise in judgment. In the gender comparison, households with more females were compared to households with more males rather than households with an equal gender distribution. This decision was motivated by the fact that gender-based differences were very small and including balanced gender households diluted them further.
Winnowing the Data
Once we decided on the encoding scheme, we generated abundance change profiles for each condition for all bacteria (Figure 8).

Figure 8. Relative differences across all bacteria and all household category comparisons.
From this table, we selected bacteria with interesting patterns—those that were both statistically significant and visually distinct across gender and pet conditions. For example Megamonas is quite similar to Conchiformibius (Figure 9) so showing both would have made for a less interesting graphic.

Figure 9. We chose bacteria that had different visual signatures.
We selected enough bacteria to fill the space on the page—it turned out that we had room for 14. At this stage we also explored other ways of presenting the decision tree questions (Figure 10).

Figure 10. Refining the design at the tight sketch phase.
Finalizing the Graphic
Encoding the ratios as circles seemed like a good direction, but we continued to explore histograms and bacterial shapes to satisfy ourselves that these were not productive directions.
We agreed that a decision tree with questions embedded at the tree branch points was the best way for a reader to explore the dataset interactively. In the final stretch of design, minor adjustments to the placement and order of the questions, as well as the position of the legend, were explored (Figure 11). We chose an orange-red to indicate an increase, with the idea that this color suggests a condition that is intensifying (higher rates of bacteria), and blue-grey to indicate a decrease.

Figure 11. Variations of the final design.
We originally planned to show the average abundance of each bacteria as a histogram, as seen in some of the earlier sketches, but eventually decided against it. The design of the page was intended to be less quantitative and more like a game, making the histogram an unnecessary graphic detail. Instead, we simply ordered the bacteria by their abundance—more abundant bacteria at the top, less abundant bacteria at the bottom. We also tried using a combination of text and icons to help explain how the baseline conditions for each comparison were chosen, but this made the graphic too busy and we ended up to relying exclusively on text to convey this information.
Details unnecessary for understanding the key message of the page were selectively removed. (This should not be confused with the act of eliminating inconvenient information). If you have the space and the reader has the time, by all means, show data patterns in the context of supporting detail. But in this case, our goal was to clarify and illustrate the main point, and avoid diffusing the key message with tangential information. All the while, keeping in mind that it was also critical to engage and delight the reader.